Document annotator for intelligent ERP systems¶
![]()
Smartscan is an is a cutting-edge data extraction tool (using OCR technology) for unstructured documents, such as invoices and receipts. The Smartscan API extracts, enriches and categorizes information details within seconds, and the output consists of a JSON document. Explore the use cases on our website.
Free Demo¶
Try our demo for free! Experience the power of the Smartscan API firsthand.
Upload your document and get the scan results within seconds using our demo application.
Quicklinks¶
- Smartscan's feature list. You can also find all available output fields in our GitHub repository. Comments in the protobuf will contain information on fields that have unique traits.
- All supported countries.
- All supported file types.
- How to start providing feedback data.
- Data Deletion Policy.
Getting started¶
Access to the API¶
-
Demo Access Token
For development purposes, you can use the demo access token
demo, like in the example below, for access to staging. Use the staging endpoints indicated in the endpoints section. Please note that this token is rate-limited and should only be used for testing. -
Staging Access Token (Recommended)
For more extensive testing and integration purposes, we recommend generating a staging access token through our Staging portal. Follow the steps in the Quick Start Guide for generating a staging or production access tokens. Refer to the Authentication for more information on the server-to-server token method.
Example request¶
POST v1/document:annotate
https://api.stag.ssn.visma.ai/v1/document:annotate
Authorization - Bearer Token¶
Token: demo
Body - raw (json)¶
Body
{ "document": { "source": { "httpUri": "http://storage.googleapis.com/vml-test-data/distributable/pdf5/10.pdf" } }, "features": [ { "type": "DEFAULT" } ], "tier": "PREMIUM" }
The response includes:
- Feedback ID: A unique identifier for each document. Read more in our feedback loop section.
- Page reference: Serves to backtrack what information was extracted and which page it was from. Read more here.
- Answers: The features that were requested and its corresponding answer. Note that the answer might not be there, if Smartscan determines that the information is not present on the document. This is shown in the example below.
- Bounding boxes: Represent the coordinates of the rectangular border that encloses a suggested field on the image of the document. Read more here.
- Confidence Level: Smartscan provides predictions accompanied by a confidence level, indicating the model's output quality. Read more here.
Example response¶
Body - raw (json)¶
Body
{ "feedbackId": "df7d8a8e-3332-40c1-bb97-aa981bcd0c4f", "answers": [ { "documentDate": [ { "value": "2015-07-09", "text": "09-07-2015", "confidence": {"level": "VERY_HIGH"}, "boundingBox": { "vertices": [{"x": 1730, "y": 732}, {"x": 1878, "y": 732}, {"x": 1878, "y": 762}, {"x": 1730, "y": 762}], "normalizedVertices": [{"x": 0.711348712, "y": 0.22276324}, {"x": 0.772203922, "y": 0.22276324}, {"x": 0.772203922, "y": 0.231892884}, {"x": 0.711348712, "y": 0.231892884}] }, "pageRef": 1, "modelMetadata": {"modelName": "layoutlm-r3", "modelVer": "1"} } ], "documentNumber": [ { "value": "1925", "text": "1925", "confidence": {"level": "VERY_HIGH"}, "boundingBox": { "vertices": [{"x": 1732, "y": 694}, {"x": 1796, "y": 694}, {"x": 1796, "y": 720}, {"x": 1732, "y": 720}], "normalizedVertices": [{"x": 0.712171078, "y": 0.21119903}, {"x": 0.738486826, "y": 0.21119903}, {"x": 0.738486826, "y": 0.219111383}, {"x": 0.712171078, "y": 0.219111383}] }, "pageRef": 1, "modelMetadata": {"modelName": "layoutlm-r3", "modelVer": "1"} } ], "paymentDueDate": [ { "value": "2015-07-17", "text": "17-07-2015", "confidence": {"level": "HIGH"}, "boundingBox": { "vertices": [{"x": 812, "y": 2900}, {"x": 996, "y": 2900}, {"x": 996, "y": 2952}, {"x": 812, "y": 2952}], "normalizedVertices": [{"x": 0.333881587, "y": 0.882531941}, {"x": 0.409539461, "y": 0.882531941}, {"x": 0.409539461, "y": 0.898356676}, {"x": 0.333881587, "y": 0.898356676}] }, "pageRef": 1, "modelMetadata": {"modelName": "layoutlm-r3", "modelVer": "1"} } ], "currency": [ { "value": "DKK", "confidence": {"level": "VERY_HIGH"}, "modelMetadata": {"modelName": "layoutlm-r3", "modelVer": "1"} } ], "totalVat": [ { "value": "585.45", "text": "585,45", "confidence": {"level": "VERY_HIGH"}, "boundingBox": { "vertices": [{"x": 2092, "y": 2650}, {"x": 2214, "y": 2650}, {"x": 2214, "y": 2686}, {"x": 2092, "y": 2686}], "normalizedVertices": [{"x": 0.860197365, "y": 0.806451619}, {"x": 0.910361826, "y": 0.806451619}, {"x": 0.910361826, "y": 0.817407191}, {"x": 0.860197365, "y": 0.817407191}] }, "pageRef": 1, "modelMetadata": {"modelName": "layoutlm-r3", "modelVer": "1"} } ], "totalInclVat": [ { "value": "2927.24", "text": "2.927,24", "confidence": {"level": "VERY_HIGH"}, "boundingBox": { "vertices": [{"x": 2066, "y": 2734}, {"x": 2222, "y": 2734}, {"x": 2222, "y": 2770}, {"x": 2066, "y": 2770}], "normalizedVertices": [{"x": 0.849506557, "y": 0.83201462}, {"x": 0.913651288, "y": 0.83201462}, {"x": 0.913651288, "y": 0.842970192}, {"x": 0.849506557, "y": 0.842970192}] }, "pageRef": 1, "modelMetadata": {"modelName": "layoutlm-r3", "modelVer": "1"} } ], "totalExclVat": [ { "value": "2341.79", "text": "2.341,79)", "confidence": {"level": "VERY_HIGH"}, "boundingBox": { "vertices": [{"x": 804, "y": 2578}, {"x": 952, "y": 2578}, {"x": 952, "y": 2618}, {"x": 804, "y": 2618}], "normalizedVertices": [{"x": 0.330592096, "y": 0.784540474}, {"x": 0.391447365, "y": 0.784540474}, {"x": 0.391447365, "y": 0.796713352}, {"x": 0.330592096, "y": 0.796713352}] }, "pageRef": 1, "modelMetadata": {"modelName": "layoutlm-r3", "modelVer": "1"} } ], "supplierCountryCode": [ { "value": "DK", "confidence": {"level": "VERY_HIGH"}, "modelMetadata": {"modelName": "layoutlm-r3", "modelVer": "1"} } ], "documentType": [ { "value": "Invoice", "confidence": {"level": "VERY_HIGH"}, "modelMetadata": {"modelName": "layoutlm-r3", "modelVer": "1"} } ], "paymentMethod": [ { "value": "BankTransfer", "confidence": {"level": "VERY_HIGH"}, "modelMetadata": {"modelName": "layoutlm-r3", "modelVer": "1"} } ], "feedbackId": "cff4fb8e-6d3b-404e-8df6-cf440562f266" } ] }
Model Versions¶
Smartscan is available in two flavors:
PREMIUMis our main model - replacing older versions of Smartscan with enhanced capabilities that was first launched in 2021.ULTRAis our top of the line model which employs both our proprietary AI as well as premium LLMs to deliver the best results in the business
Speed or performance¶
PREMIUM uses our own lightning fast proprietary AI and is ideal for interactive situations where response time is almost as important as AI quality. PREMIUM is available in two API flawors - synchronous and asynchronous.
ULTRA combines our proprietary AI with assistance from top flight reasoning LLMs to deliver results that are significantly better than the sum of the parts. This introduces additional processing time, so the ULTRA tier is only available using our asynchronous API.
Document Data Sources¶
You can provide the document in one of two ways:
- By URI: Provide a URL to the file (as shown in the example request)
- By Content: Send the file directly in the request body using the
contentfield (as shown in the example below).
Proper Base64 Encoding for content Field¶
The content field requires the raw binary bytes of the file, Base64 encoded.
- Read the file in binary mode (e.g.,
rbin Python,FileInputStreamin Java) - Base64 encode those raw bytes directly
- Send the Base64-encoded binary data in the
contentfield
Example request¶
POST v1/document:annotate¶
https://api.stag.ssn.visma.ai/v1/document:annotate
Authorization - Bearer Token¶
Token: demo
Body - raw (json)¶
Body
{ "document": { "content": "Vl00oANHjF3gxaYT4fQ0PSDJwwZIuMLl0GdNlgyKhF4KYOtcH3r... -- this is unfinished base64 enconding --" }, "features": [ { "type": "DEFAULT" } ], "tier": "PREMIUM" }
Confidence Levels¶
Smartscan provides predictions accompanied by a confidence level, indicating the model's output quality. The allowed confidence level values are as follows:
VERY_HIGH, HIGH, MID, LOW, VERY_LOW
Higher confidence levels suggest more accurate predictions. By default, we display suggestions with the highest confidence. We filter results based on confidence thresholds (HIGH or VERY HIGH) to enhance accuracy.
You can customize confidence levels in your Smartscan requests, filtering results according to your desired confidence threshold, such as VERY HIGH. However, raising confidence levels may yield fewer suggestions.
Results are sorted by confidence level, from most to least confident.
VERIFIED¶
With Smartscan's Verified functionality we introduce an additional value for the confidence level VERIFIED. Results that have been verified are cross checked with other results for greater precision. This is enabled by requesting the VERIFIED feature.
Bounding Boxes¶
In the Smartscan API, bounding boxes play a crucial role in extracting meaningful information from documents. A bounding box represents the coordinates of the rectangular border that encloses a suggested field on the image of the document, as shown in the image below. Utilising bounding boxes empowers you to precisely pinpoint and extract specific data, enhancing the accuracy and efficiency of your document processing.
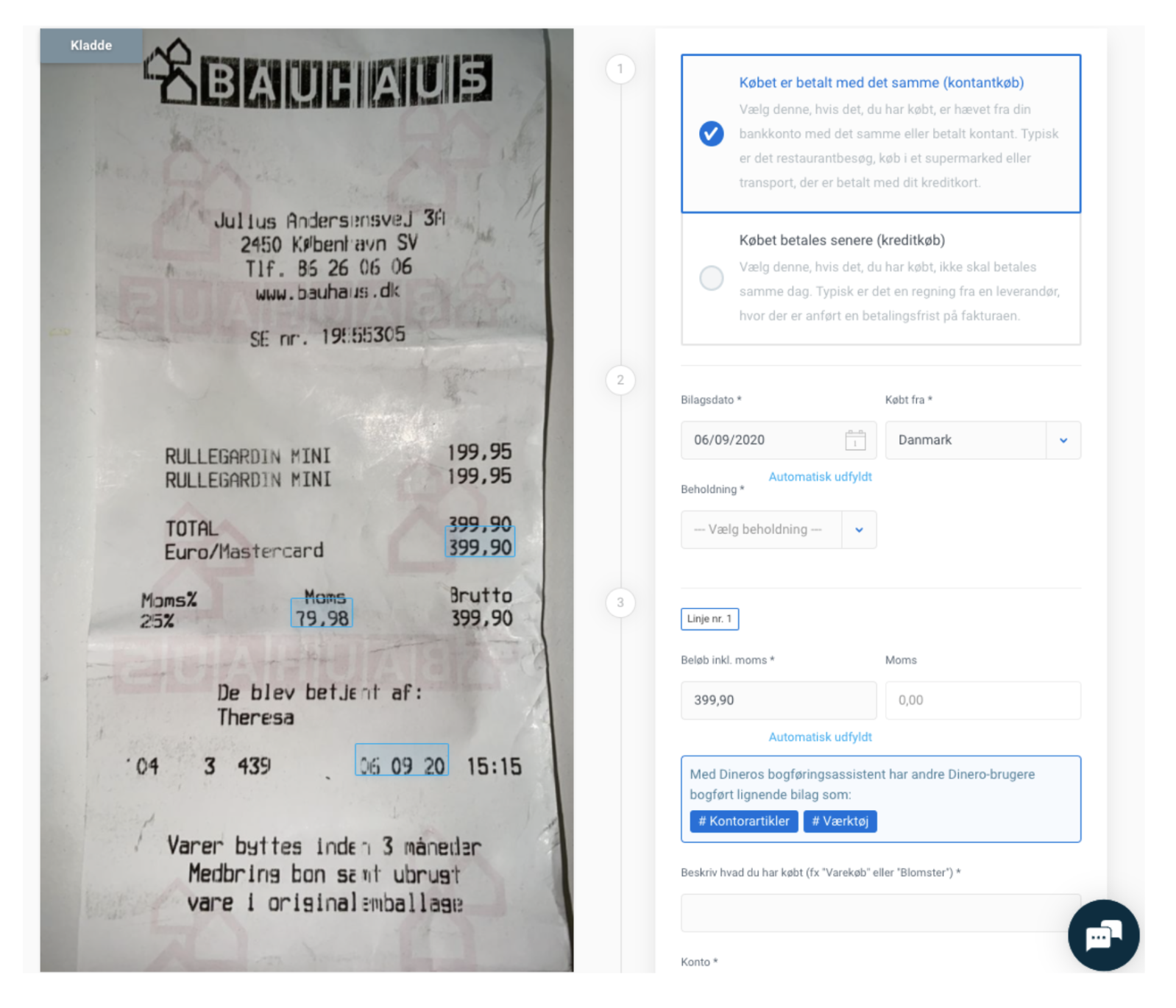
How to Implement Bounding Boxes¶
When making API requests, include bounding box coordinates to define the region of interest within the document. Here's a basic example:
{
"bounding_box": {
"top_left": {"x": 100, "y": 150},
"bottom_right": {"x": 300, "y": 250}
},
// Other request parameters...
}
Page references¶
Pageref references to the number of the suggested field's page.
- When you send a document that is only one page long, Smartscan returns pageref of 1.
- When you send a document that is two or more pages long, Smartscan only reads the first and last page. As an example, if the document is four pages long, the pageref will return pageref of 1 and 4.
The bounding box and pagerefs is present on majority of the fields.
Supported countries¶
Smartscan currently supports 51 countries, and we're continuously working to expand this list. Below is the complete list of supported countries:
"AL", "AT", "AU", "BA", "BE", "BG", "BY", "CA", "CH", "CN", "CY", "CZ","DE", "DK", "EE", "EL", "ES", "FI", "FO", "FR", "GB", "GL", "HR", "HU", "IE", "IS", "IT", "LI", "LT", "LU", "LV", "MC", "MD", "ME", "MK", "MT", "NL", "NO", "NZ", "PL", "PT", "RO", "RS", "RU", "SE", "SI", "SK", "TR", "UA", "US", "XK"
Supported file types¶
Below is the complete list of supported image types:
- PDF containing text (Recommended)
- PDF containing images (most often from scanners)
- JPG / JPEG (Recommended)
- PNG
- BMP
- webp
- tif
- gif
- bmp
- heif/heic
In addition, Smartscan processes all text the OCR is able to scan. This can include handwritten receipts on standard pads.